
この記事は個人の学習・検証目的で、Pythonの基本的なスクレイピング手法を紹介するものです。
対象サイト(go2senkyo.com)は公に公開されている情報を扱っていますが、取得したデータを再配布・商用利用する意図は一切ありません。
個人での分析や学習用途に限定し、もしサイト運営者から問題の指摘があった場合は、速やかに記事を削除または修正いたします。
今回、go2senkyo.com に掲載されている「葛飾区議会議員選挙(2025)」の候補者一覧をPythonでスクレイピングするプログラムを作ってみました。CSVファイルを出力します。
Pythonでのスクレイピングは非常に便利ですが、アクセス負荷や著作権・利用規約の点に十分注意する必要があります。
本記事は学習・技術検証目的であり、データの再配布・商用利用は禁止とします。
11/07追記 活用例:ExcelにCSVファイルを読み込み
例えば特定の所属政党でフィルタリング、特定の所属政党を除いてフィルタリング等、投票検討に活用可能。
今回、私は無所属、新人、年齢条件でフィルタリング、5名程度に絞り込みを行い、その5人について、政策やお人柄、SNS活動などを確認、投票先を決定しようとしています。

事前準備
Pythonの実行環境ある人は不要と思います。不足がある場合は、適宜追加してください。
sudo apt update
sudo apt install -y python3 python3-venv python3-pip仮想環境を作る(必須ではありません)
補足:本記事では仮想環境(venv)を使う方法を紹介していますが、環境を分ける必要がない場合は作らなくても大丈夫です。
mkdir ~/katsushika-2025
cd ~/katsushika-2025
python3 -m venv venv
source venv/bin/activate必要ライブラリをインストール
pip install beautifulsoup4 requests lxml適宜追加してください。
作成したスクリプト:go2senkyo_extractor.py
#!/usr/bin/env python3
import requests, csv, re, time, random
from bs4 import BeautifulSoup
URL = "https://go2senkyo.com/local/senkyo/25126"
HEADERS = {"User-Agent": "Mozilla/5.0 (compatible; ElectionScraper/1.0)"}
def fetch(url):
for i in range(3):
try:
res = requests.get(url, headers=HEADERS, timeout=10)
if res.status_code == 200:
return res.text
except Exception as e:
print(f"retry {i+1}: {e}")
time.sleep(random.uniform(2, 5))
raise Exception("ページ取得失敗")
html = fetch(URL)
soup = BeautifulSoup(html, "lxml")
rows = soup.select("section.m_senkyo_result_data")
records = []
for row in rows:
name_tag = row.select_one("h2 a")
kana_tag = row.select_one("span.m_senkyo_result_data_kana")
name = name_tag.contents[0].strip() if name_tag and name_tag.contents else ""
kana = kana_tag.get_text(strip=True) if kana_tag else ""
para = row.select_one(".m_senkyo_result_data_para")
age, gender, jobtype = "", "", ""
if para:
text = para.get_text(" ", strip=True)
m = re.search(r"(\d+)歳\s*\((男|女)\)\s*(現職|新人)?", text)
if m:
age, gender, jobtype = m.group(1), m.group(2), m.group(3) or ""
party = row.select_one(".m_senkyo_result_data_circle")
party = party.get_text(strip=True) if party else ""
remark_tag = row.select_one(".m_senkyo_result_data_para.small")
remark = remark_tag.get_text(strip=True) if remark_tag else ""
records.append([name, kana, age, gender, jobtype, party, remark])
with open("senkyo_candidates_from_web.csv", "w", newline="", encoding="utf-8-sig") as f:
writer = csv.writer(f)
writer.writerow(["名前", "よみがな", "年齢", "性別", "職種区分", "所属政党", "備考"])
writer.writerows(records)
print(f" {len(records)}件の候補者データを取得しました。")
実行
python go2senkyo_extractor.pyプログラム実行に成功すると、senkyo_candidates_from_web.csvが生成されます。
# python go2senkyo_extractor.py
65件の候補者データを取得しました。
# ls *.csv
senkyo_candidates_from_web.csv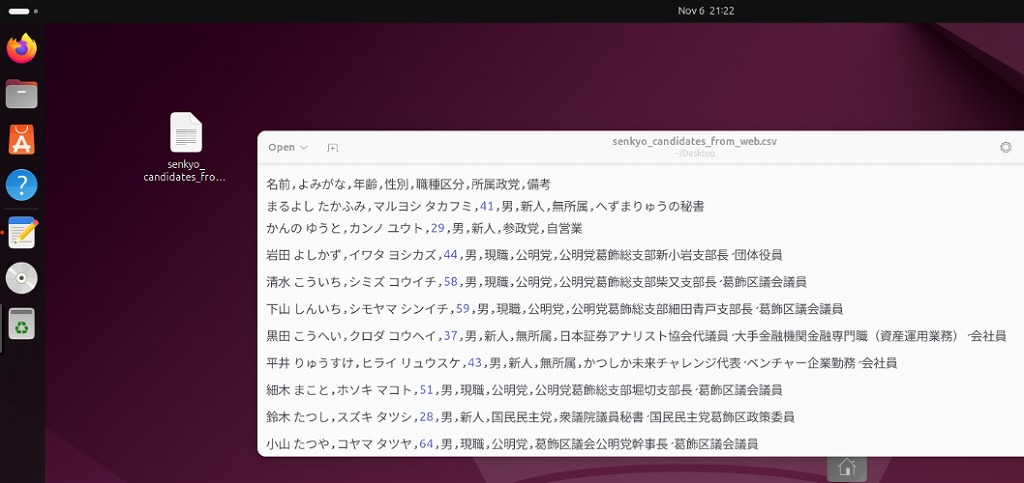
マナーと法的配慮
- アクセス間隔をランダム(2〜5秒)に設定済み
- 1日1回以下の実行を推奨。
- 一応、適当なUser-Agentを明示しています。
- データは個人学習・分析用途限定してください。取得したCSVデータの再配布はだめですよ。
免責事項
本記事で紹介している内容は、筆者の個人的な学習・検証を目的とした技術的な検証結果です。
掲載されているプログラムやコードの利用によって発生したいかなる損害・トラブルについても、筆者は一切の責任を負いません。
また、対象サイト(go2senkyo.com)の運営方針や利用規約の変更により、本記事の内容が将来的に適用外となる場合があります。実際にデータ取得を行う際は、必ずご自身で最新の利用規約を確認し、適切な範囲での利用をお願いいたします。
※Pythonプログラムのサポートはしておりません。
最後に
65人の候補者さんの名簿が欲しかったので、作成してみました。候補者が多いのはいいことです。選ぶのちょっと大変になります。なんで、PDFとか縦書きなんだろう。あんまりいい名簿データがないのです。見つけられていないだけかもしれません。
CSVファイルをそのまま配ると怒られそうなので、スクレイピング手法として記事を書いてみました。ご利用は自己責任でお願いします。
他の地方選挙URLでも、ひょっとしたら、差し替えるだけで再利用可能かも。テーブル構造が変わっていなければいけるか?
名簿をExcelに読み込んでフィルタリングやソートをするなど、投票検討資料として使おうとしています。
ということで、期日前投票投票いってきます!
選挙公報等、下記リンクから確認できます。一応、ペーパーは全戸配布されていると思います。
葛飾区議会議員選挙・葛飾区長選挙 >候補者を選ぶためにhttps://www.city.katsushika.lg.jp/information/1000080/1020036/1014529/1015898.html
